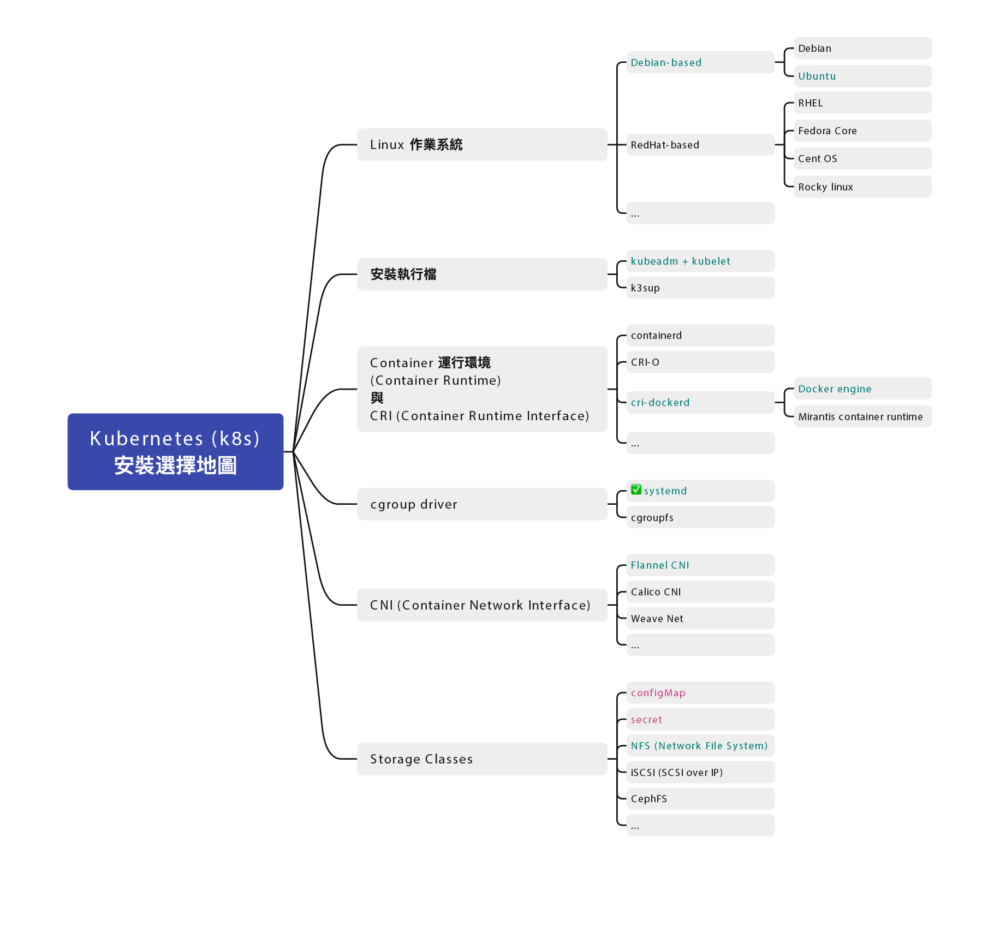
後來做了很多研究,分享我的 Kubernetes (K8s) 標準架設方式。
因為 Kubernetes (K8s) 套件一直更新,步驟已經有一點不太一樣了,
再加上我有小小更換一些元件,感覺值得再寫一次
沒意外的話,會來個大改版,到時候可能又要再寫一次(笑)
這次一樣分二個版本 Ubuntu 版本跟 Redhat 版本
如果想要參考以前的文章可以參考這裡:
廢話不多說,我們開始
預期得到的成果
- Ubuntu 24.04 LTS
- Vanilla Kubernetes (via kubeadm) 1.34.2
- docker v29.1.2 (containerd: v2.2.0)
- cri-docker 0.3.20 (b11203a)
- calico v3.29.2
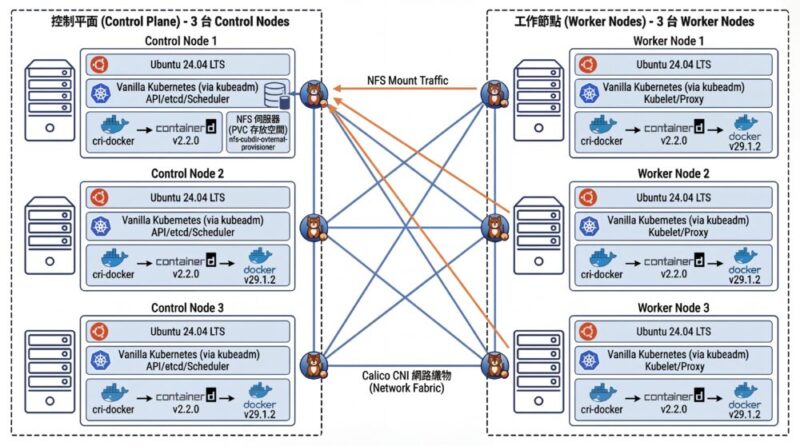
- 三台
Control node與 三台Worker Node標準配置 - 使用 NFS 存放 PVC 空間 (nfs-subdir-external-provisioner)
- Metrics Server
架構圖
Kubernetes 安裝步驟
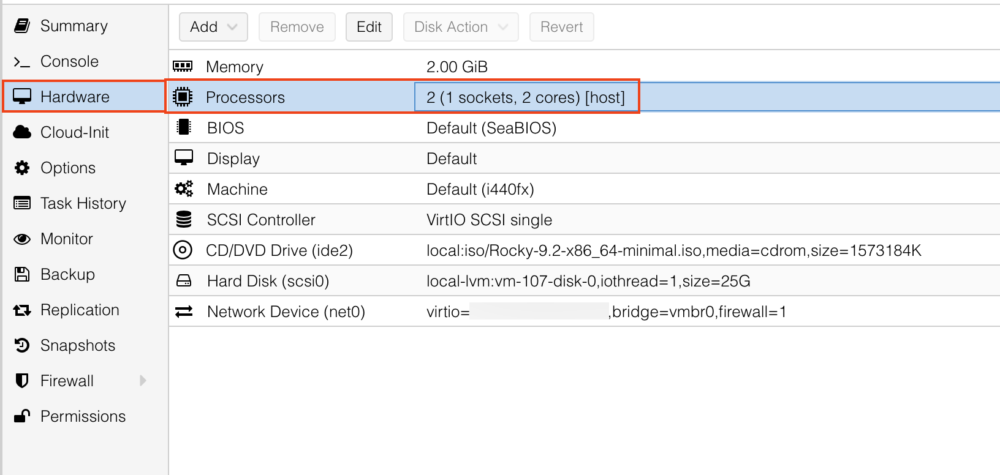
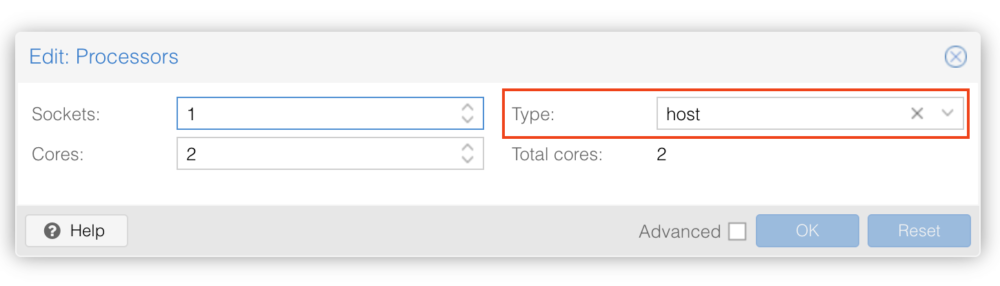
Step 0. 虛擬機硬體建置
這邊是我 虛擬機 (VM) 的硬體部分建置設定
(最小實驗性質的資源規格,正式機不建議使用這個規格)
- 2 CPU
- 4GB Ram
- 10GB Disk 以上,建議 30GB 較穩定
到時候要建立六台 VM,三台 Control Node 跟三台 Worker Node ,這是標準叢集的配置。
如果你要把三台 Control Node 兼用 Worker Node 校長兼撞鐘,也可以,但不建議,後面會告訴你怎麼設定。
Step 1. <每台都做> 安裝 Docker
Docker 不分角色,三台都要裝
安裝文件:
https://docs.docker.com/engine/install/ubuntu/
小弟整理的一鍵安裝指令
(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
apt-get update -m -y && \
apt-get install -y ca-certificates curl && \
install -m 0755 -d /etc/apt/keyrings && \
curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc && \
chmod a+r /etc/apt/keyrings/docker.asc && \
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
tee /etc/apt/sources.list.d/docker.list > /dev/null && \
apt-get update -y && \
apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin修改 daemon.json 讓跳開預設網段
(如果沒有該檔案請自行新增之)
sudo vi /etc/docker/daemon.json內容為
{
"log-driver": "json-file",
"log-opts": {
"tag": "{{.Name}}",
"max-size": "2m",
"max-file": "2"
},
"default-address-pools": [
{
"base": "172.31.0.0/16",
"size": 24
}
],
"bip": "172.7.0.1/16"
}設定 docker 預設開機啟動
sudo systemctl enable --now docker驗證 Docker
可用 systemctl 指令查看是否有正常執行
sudo systemctl status docker看看是否有 Running
可以用 docker ps 查看目前所有運行中的 container
docker ps是否能夠正常顯示列表,若是初次安裝,列表是空的很正常。
Step 2. <每台都做> 關掉 swap
這步驟不分角色,六台都要做,雖然最新版本有(有限度的)支援 Swap
但我還是先建議把 Swap 關掉,以確保叢集的穩定性。
我們用以下步驟永久關閉 Swap:
- 用
sed指令找尋 swap 片段,並加上註解
sudo sed -i '/ swap /s/^/#/g' /etc/fstab- 然後重新載入磁區
sudo mount -a暫時關閉 swap 可以用 swapoff 指令
sudo swapoff -a確認 swap
我們用 free 指令就可以看到 Swap 有沒有啟用了
freeStep 3. <每台都做> 安裝 kubelet、kubeadm、kubectl 三兄弟
安裝文件:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
加入 K8s 套件參考
安裝 kubelet kubeadm kubectl
(指定版本 1.34.2)
sudo apt update -y && \
sudo apt-get install -y apt-transport-https ca-certificates curl && \
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg && \
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.32/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list && \
sudo apt-get update -y && \
sudo apt-get install -y kubelet=1.34.2-1.1 kubeadm=1.34.2-1.1 kubectl=1.34.2-1.1 && \
sudo apt-mark hold kubelet kubeadm kubectl(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
這邊我有修改指定版本號
若你想查詢所有的版本,可以用以下指令
顯示所有版號
apt show kubelet -a | less再修改指令上去
Step 4. <每台都做> 安裝 Container Runtime Interface (CRI) – cri-dockerd
這步驟不分角色,三台都要裝
https://kubernetes.io/docs/setup/production-environment/container-runtimes/
我們用 Docker Engine 推薦的 cri-dockerd
查看最新版本一樣沒有 24.04 (noble)
從官網手動安裝 Golang
如果你的 apt-get 套件庫的 Golang 不夠新的話
我在 Redhat 那邊有遇到這情況,我把說明文件先放在這裡
到 Golang 的官網下載最新版本的 Golang 例如 1.23.2
wget https://go.dev/dl/go1.23.2.linux-amd64.tar.gz解壓縮 go1.23.2.linux-amd64.tar.gz 檔案,會得到 go 資料夾,把他搬到對應位置
tar zxvf go1.23.2.linux-amd64.tar.gz
sudo mv go /usr/lib/golang然後建立捷徑
sudo ln -s /usr/lib/golang/bin/go /usr/bin/go使用 go version 來確認版本
go version內容如下
$ go version
go version go1.23.2 linux/amd64手動編譯安裝 cri-dockerd
如果是 Ubuntu 24.04.1 LTS (Noble Numbat)
如果找不到你的版本,可能要手動編譯並安裝
以下是官方文件提供的步驟
https://github.com/mirantis/cri-dockerd#build-and-install
https://mirantis.github.io/cri-dockerd/usage/install-manually/
安裝 make 與 golang 套件
sudo apt install -y make golang用 git clone 最新的版本
git clone https://github.com/Mirantis/cri-dockerd.git編譯它 (compile)
cd cri-dockerd && \
make cri-dockerd安裝
cd cri-dockerd && \
mkdir -p /usr/local/bin && \
install -o root -g root -m 0755 cri-dockerd /usr/local/bin/cri-dockerd && \
install packaging/systemd/* /etc/systemd/system && \
sed -i -e 's,/usr/bin/cri-dockerd,/usr/local/bin/cri-dockerd,' /etc/systemd/system/cri-docker.service然後請 systemctl 重新載入 daemon
最後啟動服務
sudo systemctl daemon-reload && \
sudo systemctl enable --now cri-docker如果是服務更新版本,需要重啟服務
sudo systemctl restart cri-docker驗證 cri-docker
可用 systemctl 指令確認是否有正常運行
sudo systemctl status cri-docker確認有 Running
確認版本號
cri-dockerd --version執行紀錄
$ cri-dockerd --version
cri-dockerd 0.3.12-16-gebd9de06 (ebd9de06)裝完就會有 unix:///var/run/cri-dockerd.sock
註:之前社群一直有人討論是否要編譯 ubuntu 24.04 (noble)
但我看下一版,應該就不使用 cri-dockerd 了
就沒繼續追蹤進度了
Step 5. 複製虛擬機 (VM)
這邊步驟就是將單純的將 虛擬機 (VM) 複製二份成三台,並全部啟動。
以下分別闡述複製完要做的事情
重新產生 Machine-id
用以下指令重新產生 Machine-id
sudo rm /etc/machine-id && \
sudo systemd-machine-id-setup修改 Hostname (主機名稱)
sudo hostnamectl set-hostname k8s-node1分別改成對應的主機名稱
重新設定 ssh,產生全新的 known-host
sudo ssh-keygen -A && \
sudo dpkg-reconfigure openssh-server確認 Machine-id
sudo cat /sys/class/dmi/id/product_uuid確認 Hostname
hostname確認網卡 Mac address 位址
ip link或者
ifconfig都可以,如果沒有 ifconfig 指令要安裝 net-tools
sudo apt install -y net-toolshttps://superuser.com/questions/636924/regenerate-linux-host-fingerprint
如果有需要的話,可以用 dhclient 指令重新取 DHCP 的 IP
(基本上你重新產生 Machine-id 的話,就會視為別台電腦了)
sudo dhclient -rStep 6. <每台都做> 設定主機對應
叢集的三台機器做出來,還不知道彼此,
這邊用 /etc/hosts 檔案來讓主機們各自找到彼此
sudo vi /etc/hosts根據每台主機的 IP 位址與主機名稱
192.168.1.100 ubuntu2404-k8s-ctrl1
192.168.1.101 ubuntu2404-k8s-ctrl2
192.168.1.102 ubuntu2404-k8s-ctrl3
192.168.1.103 ubuntu2404-k8s-worker1
192.168.1.104 ubuntu2404-k8s-worker2
192.168.1.105 ubuntu2404-k8s-worker3IP 位址在前,主機名稱在後,用 tab 分隔。
先整理好內容,再各自寫在每一台上面,每一台主機都會看到同一份資料。
Step 7. <每台都做> 設定網路雜項值
這邊設定網路連線轉發 IPv4 位址並讓 iptables 查看橋接器的流量
用文件提供的指令操作,等等一句一句解釋:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF請 Kubernetes (K8s) 引用載入 br_netfilter, overlay 二個核心模組
sudo modprobe overlay && \
sudo modprobe br_netfilter啟用 br_netfilter, overlay 二個核心模組
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF設定轉發 IPv4 位址,讓 iptables 查看橋接器的流量
sudo sysctl --system再不起重新啟動電腦情況下,套用設定值
檢查驗證
檢查 br_netfilter, overlay 二個核心模組有沒有被正確載入可以用以下二個指令
lsmod | grep br_netfilter
lsmod | grep overlay檢查
net.bridge.bridge-nf-call-iptablesnet.bridge.bridge-nf-call-ip6tablesnet.ipv4.ip_forward
這幾個系統變數是否有設定為 1,可以用 sysctl 指令來檢查:
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forwardStep 8. 設定第一台 Control plane node(控制平台)
終於要來設定 Control plane (控制平台) 了,如果有其他教學看到 Master node 的話,
別擔心,指的是同一件事情。
利用 kubeadm init 指令來初始化,並代入這些參數:
sudo kubeadm init \
--kubernetes-version 1.34.2 \
--control-plane-endpoint=192.168.1.100 \
--apiserver-advertise-address=192.168.1.100 \
--node-name k8s-ctrl \
--pod-network-cidr=10.244.0.0/16 \
--cri-socket unix:///var/run/cri-dockerd.sock參數說明
control-plane-endpoint
指明 Control plane (控制平台) 是哪個網址,這邊設定好目前這台 IP 位址即可,假設為 192.168.1.100
(這設定值可省略)apiserver-advertise-address
指明 API server 的廣播地址,預設就是 Control plane (控制平台) IP 位址,假設為 192.168.1.100
(這設定值可省略)node-name
指明 Control plane (控制平台) 的名字,這裡跟主機名稱一致即可,注意大小寫底線,有些字元是不允許的。pod-network-cidr
指明 pod 內部網路使用的網段,這邊因為配合 Flannel CNI,請保留10.244.0.0/16先不要修改,除非你知道在做什麼。cri-socket
指明使用的 CRI 使用unix:///var/run/cri-dockerd.sock這設定值 請不要修改。
會一路安裝第一台設定好為 control node
註:如果有需要,可以事先先下載 image
使用這指令
kubeadm config images pull --cri-socket unix:///var/run/cri-dockerd.sock --kubernetes-version 1.34.2如果沒意外的話,完成之後會看到
Your Kubernetes control-plane has initialized successfully!才成功三成而已,還沒完成!後續還要接續設定
Step 9. <在第一台 Control-node 做> 複製金鑰與證書
資料準備
在第一台 Control node 做操作
建立資料夾,假設路徑在 /tmp/k8s-certs 底下
mkdir -p /tmp/k8s-certs && \
mkdir -p /tmp/k8s-certs/etcd我們需要複製以下檔案
.
├── ca.crt
├── ca.key
├── etcd
│ ├── ca.crt
│ └── ca.key
├── front-proxy-ca.crt
├── front-proxy-ca.key
├── sa.key
└── sa.pub
1 directory, 8 files所以指令如下
sudo cp -r /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} /tmp/k8s-certs/ && \
sudo cp -r /etc/kubernetes/pki/etcd/ca.* /tmp/k8s-certs/etcd/注意不要多複製其他檔案,不然到時候建立會有問題
複製到其他節點
我們就假設你都在第一台 Control node 做操作
我們把 /tmp/k8s-certs 資料夾複製到其他節點
scp -r /tmp/k8s-certs [email protected]:/tmp/
scp -r /tmp/k8s-certs [email protected]:/tmp/然後 ssh 分別登入到另外二個節點
ssh [email protected]在另外兩個節點中,建立資料夾,並複製檔案
把剛剛的那幾個金鑰複製到指定 K8s 位置 /etc/kubernetes/pki/
mkdir -p /etc/kubernetes/pki/ && \
cp -R /tmp/k8s-certs/* /etc/kubernetes/pki/注意如果做錯了需要下 kubeadm reset 重來的時候, /etc/kubernetes/pki/ 金鑰也會被清空掉,所以要再複製一次
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sockStep 10. <在另外二台 Control node 做> 加入成爲 Control node
這邊就比較特別,因為剛剛的金鑰複製步驟做完之後,
就可以用指令重新生成加入指令
kubeadm token create --print-join-command然後你就會得到一串加入指令,假設長這樣
kubeadm join 192.168.1.100:6443 --token 2xxxxc.6bxxxxxxxxxxxx96 \
--discovery-token-ca-cert-hash sha256:b84fxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxc6b4這時候你就可以在第二台與第三台 Control node 上執行類似這樣的指令
kubeadm join 192.168.1.100:6443 --token 2xxxxc.6bxxxxxxxxxxxx96 \
--discovery-token-ca-cert-hash sha256:b84fxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxc6b4 \
--control-plane --cri-socket unix:///var/run/cri-dockerd.sock加上 --control-plane 參數,讓這台節點成為 Control node
還有加上 --cri-socket unix:///var/run/cri-dockerd.sock 參數,讓 kubeadm 知道你使用的是 cri-dockerd
這樣就完成了
你可以用 kubectl get node 查看一下
# kubectl get node node
NAME STATUS ROLES AGE VERSION
ubuntu2404-k8s-ctrl1 NotReady control-plane 3m22s v1.34.2
ubuntu2404-k8s-ctrl2 NotReady control-plane 9s v1.34.2
ubuntu2404-k8s-ctrl3 NotReady control-plane 5s v1.34.2這邊因為還沒有設定 CNI,所以 STATUS 為 NotReady 是 正常現象
(叢集才設定一半,還沒設定網路,當然顯示 K8s 叢集不可用)
Step 11. <在 Worker node 做> 加入 Worker node
如果要加入 Worker node,可以使用 kubeadm join 指令
可以在其中一台 Control code 用指令重新生成加入指令
kubeadm token create --print-join-command然後你就會得到一串加入指令,假設長這樣
kubeadm join 192.168.1.100:6443 --token 2xxxxc.6bxxxxxxxxxxxx96 \
--discovery-token-ca-cert-hash sha256:b84fxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxc6b4這時候你就可以在 Worker node 上執行類似這樣的指令
kubeadm join 192.168.1.100:6443 --token 2xxxxc.6bxxxxxxxxxxxx96 \
--discovery-token-ca-cert-hash sha256:b84fxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxc6b4 \
--cri-socket unix:///var/run/cri-dockerd.sock沒有意外的話,就可以正常加入了
其他台 Worker node 也是一樣的操作
Step 12. 設定 Calico CNI 網路
參考文件
https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
註:這邊 Calico CNI 也不停的一直在更新版本,步驟會略有一些差異,這邊本就文字記錄,
請時時刻刻查詢官方文件,實際以官方文件撰寫的為主
筆者撰文的時候 calico v3.29.2
文件在此
https://docs.tigera.io/calico/3.29/getting-started/kubernetes/quickstart
Murmur: 以前 v3.14 版本之前本來只有
calico.yaml一個檔案,
後來改成tigera-operator.yaml跟custom-resources.yaml二個檔案了,不影響操作
根據文件,第一步要建立 tigera-operator.yaml 的內容
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.29.2/manifests/tigera-operator.yaml要注意 calico 的版本號
另一個要注意,這指令一定要使用 kubectl create,不能使用 kubectl apply 指令替代
不然會有錯誤
第二步要建立 custom-resources.yaml 的內容
這邊我們修改一下,先把檔案抓下來
wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.2/manifests/custom-resources.yaml然後修改 custom-resources.yaml 的內容
vi custom-resources.yamlapiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}將 cidr 的值,原本是 192.168.0.0/16,改成我們使用 --pod-network-cidr 參數的值:10.244.0.0/16
其實也只是因為我們外面主機已經使用 192.168.0.0/16 的網段了,所以內部 K8s 跑的網段改成跟主機不一樣的 10.244.0.0/16
然後執行建立指令
kubectl create -f custom-resources.yaml我這邊也列一下 calico v3.29.2 會用到的 image,供參考
(每一個版本可能用的 image 版號也會不同)
quay.io/tigera/operator:v1.36.5
docker.io/calico/typha:v3.29.2
docker.io/calico/node-driver-registrar:v3.29.2
docker.io/calico/csi:v3.29.2
docker.io/calico/pod2daemon-flexvol:v3.29.2
docker.io/calico/node:v3.29.2
docker.io/calico/kube-controllers:v3.29.2
docker.io/calico/cni:v3.29.2
docker.io/calico/apiserver:v3.29.2Step 13. 設定 Control node 兼 Worker node (選擇性)
如果你需要 Control node 兼 Worker node 校長兼撞鐘,
你可以使用這個指令移除 taint
(如有需求再使用)
kubectl taint nodes --all node-role.kubernetes.io/control-plane:NoSchedule-筆記一下,舊版指令如下
kubectl taint nodes --all node-role.kubernetes.io/master-測試驗證
驗證
kubectl get pods -A全部都要是 Running 的狀態
像這樣
# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-system calico-node-nzl6r 0/1 Running 0 37s
calico-system calico-node-xp467 1/1 Running 0 39s
calico-system calico-node-xt9xg 1/1 Running 0 39s
calico-system calico-typha-6b99cb568-d8t92 1/1 Running 0 102s
calico-system calico-typha-6b99cb568-xsq5f 1/1 Running 0 101s
kube-system coredns-66bc5c9577-556g8 1/1 Running 0 44m
kube-system coredns-66bc5c9577-vwh6x 1/1 Running 0 44m
kube-system etcd-ubuntu2404-k8s-ctrl1 1/1 Running 0 44m
kube-system etcd-ubuntu2404-k8s-ctrl2 1/1 Running 0 41m
kube-system etcd-ubuntu2404-k8s-ctrl3 1/1 Running 0 41m
kube-system kube-apiserver-ubuntu2404-k8s-ctrl1 1/1 Running 0 44m
kube-system kube-apiserver-ubuntu2404-k8s-ctrl2 1/1 Running 0 41m
kube-system kube-apiserver-ubuntu2404-k8s-ctrl3 1/1 Running 0 41m
kube-system kube-controller-manager-ubuntu2404-k8s-ctrl1 1/1 Running 0 44m
kube-system kube-controller-manager-ubuntu2404-k8s-ctrl2 1/1 Running 0 41m
kube-system kube-controller-manager-ubuntu2404-k8s-ctrl3 1/1 Running 0 41m
kube-system kube-proxy-gssk9 1/1 Running 0 44m
kube-system kube-proxy-shls8 1/1 Running 0 41m
kube-system kube-proxy-xtsfw 1/1 Running 0 41m
kube-system kube-scheduler-ubuntu2404-k8s-ctrl1 1/1 Running 0 44m
kube-system kube-scheduler-ubuntu2404-k8s-ctrl2 1/1 Running 0 41m
kube-system kube-scheduler-ubuntu2404-k8s-ctrl3 1/1 Running 0 41m
tigera-operator tigera-operator-6dc5767955-cfshr 1/1 Running 0 2m58skubectl get nodes -o wide要看到所有節點都有 Ready 的狀態
像這樣
# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ubuntu2404-k8s-ctrl1 Ready control-plane 46m v1.34.2 192.168.1.100 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2
ubuntu2404-k8s-ctrl2 Ready control-plane 43m v1.34.2 192.168.1.101 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2
ubuntu2404-k8s-ctrl3 Ready control-plane 43m v1.34.2 192.168.1.102 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2
ubuntu2404-k8s-worker1 Ready None 43m v1.34.2 192.168.1.103 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2
ubuntu2404-k8s-worker1 Ready None 43m v1.34.2 192.168.1.104 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2
ubuntu2404-k8s-worker1 Ready None 43m v1.34.2 192.168.1.105 <none> Ubuntu 24.04.3 LTS 6.8.0-88-generic docker://29.1.2版本資訊
只是做個紀錄
# docker version
Client: Docker Engine - Community
Version: 29.1.2
API version: 1.52
Go version: go1.25.5
Git commit: 890dcca
Built: Tue Dec 2 21:55:14 2025
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 29.1.2
API version: 1.52 (minimum version 1.44)
Go version: go1.25.5
Git commit: de45c2a
Built: Tue Dec 2 21:55:14 2025
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v2.2.0
GitCommit: 1c4457e00facac03ce1d75f7b6777a7a851e5c41
runc:
Version: 1.3.4
GitCommit: v1.3.4-0-gd6d73eb8
docker-init:
Version: 0.19.0
GitCommit: de40ad0# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"34", EmulationMajor:"", EmulationMinor:"", MinCompatibilityMajor:"", MinCompatibilityMinor:"", GitVersion:"v1.34.2", GitCommit:"8cc511e399b929453cd98ae65b419c3cc227ec79", GitTreeState:"clean", BuildDate:"2025-11-11T19:08:36Z", GoVersion:"go1.24.9", Compiler:"gc", Platform:"linux/amd64"}# kubectl version
Client Version: v1.34.2
Kustomize Version: v5.7.1
Server Version: v1.34.2# cri-dockerd --version
cri-dockerd 0.3.20 (b11203a)Troubleshooting 疑難排解
如果你遇到類似的錯誤
# kubeadm join 192.168.1.100:6443 --token kkxxxx.xxxxxxxxxxxxxdl2 --discovery-token-ca-cert-hash sha256:bdfxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx19c --control-plane --cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks
[preflight] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[preflight] Use 'kubeadm init phase upload-config --config your-config.yaml' to re-upload it.
error execution phase preflight:
One or more conditions for hosting a new control plane instance is not satisfied.
[failure loading certificate for CA: couldn't load the certificate file /etc/kubernetes/pki/ca.crt: open /etc/kubernetes/pki/ca.crt: no such file or directory, failure loading key for service account: couldn't load the private key file /etc/kubernetes/pki/sa.key: open /etc/kubernetes/pki/sa.key: no such file or directory, failure loading certificate for front-proxy CA: couldn't load the certificate file /etc/kubernetes/pki/front-proxy-ca.crt: open /etc/kubernetes/pki/front-proxy-ca.crt: no such file or directory, failure loading certificate for etcd CA: couldn't load the certificate file /etc/kubernetes/pki/etcd/ca.crt: open /etc/kubernetes/pki/etcd/ca.crt: no such file or directory]
Please ensure that:
* The cluster has a stable controlPlaneEndpoint address.
* The certificates that must be shared among control plane instances are provided.
To see the stack trace of this error execute with --v=5 or higher遇到這段
failure loading certificate for CA: couldn't load the certificate file應該是沒有正確複製金鑰
除錯
如果有遇到問題,可以這樣觀察
查看 kubelet 的狀態
systemctl status kubelet查看 kubelet 的 Log
journalctl -xeu kubelet這樣最基礎的 K8s 加上網路就完成了
Persistent Volumes (PV) 磁碟相關設定
基本上會需要一個共用空間來配置 Persistent Volumes (PV)
我們可以用 NFS 來做為該共用空間
這邊可能就比較雜項一點,但如果沒有設定好,
應用程式設定 Persistent Volume Claim (PVC) 是不會有動作的,
狀態會卡住無法正確部署
安裝 nfs-server (Optional)
剛剛有提到,我們使用 NFS 來作為存放 Persistent Volumes (PV) 的地方,
需要一個 NFS 的位置,這個可以是你的 NAS,也可以是台電腦,
也可以是 TrueNAS 或者 OpenMediaVault (OMV),總之做法很多,
這邊示範如果你什麼都沒有,只有 Ubuntu 主機,如何直接在上面裝一個 NFS 伺服器。
安裝 nfs-server
sudo apt install nfs-kernel-server nfs-common -y假設我們要共用的資料夾路徑為 /export/k8s-space
所以我們來開 /export/k8s-space 資料夾
mkdir -p /export && \
mkdir -p /export/k8s-space編輯 /etc/exports 設定檔
vi /etc/exports內容為
/export/k8s-space 192.168.1.0/24(rw,subtree_check,insecure)
/export 192.168.1.0/24(rw,root_squash,no_subtree_check,hide)這邊 IP 設定可存取的網段,假設為 192.168.1.0/24,請依需求修改
啟動 nfs 服務
sudo systemctl start --now nfs-kernel-server.service如果 /etc/exports 設定檔有更新,記得用指令更新 nfs 檔案清單
exportfs -a設定與安裝 nfs-subdir-external-provisioner
這塊就是 K8s 的範疇,
使用 helm 來安裝 nfs-subdir-external-provisioner
他會做一件事情,持續偵測 K8s 狀態,
當收到 PVC 請求的時候,在 nfs 開一個指定的資料夾,當成 PV
然後掛載在 PVC 上
加入 helm repo 參考
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner
helm repo update產生 helm charts 參數
helm show values nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
--version 4.0.18 > nfs-values.yaml它會產生一個預設的 nfs-values.yaml 供你修改
修改 nfs-values.yaml
這就是重頭戲,修改 nfs-values.yaml
vi nfs-values.yaml修改的片段如下,請依需求修改
image:
repository: registry.k8s.io/sig-storage/nfs-subdir-external-provisioner
tag: v4.0.2
pullPolicy: IfNotPresent
#imagePullSecrets:
#- name: regcred設定值說明
image.repository與image.tag: image 的位址,通常情況私有部署時,
會把 image 放進私有的 Registry,所以會對應修改這些值image.pullPolicy:部署時拉取的策略,常用值可以是IfNotPresent(如果沒有的話才從遠端下載) 或Always(總是每次都從遠端下載)imagePullSecrets.name:私有 Registry 的登入資訊
nfs:
server: 192.168.1.2
path: /export/k8s-space
mountOptions:
volumeName: nfs-subdir-external-provisioner-root
# Reclaim policy for the main nfs volume
reclaimPolicy: Delete設定值說明
nfs.server:NFS 伺服器位址,請依需求修改nfs.path:NFS 的遠端路徑,請依需求修改nfs.reclaimPolicy: 如果 PVC 刪除之後的該空間的預設動作處理,
常用值為 Retain (保留) 與 Delete (刪除),
若是 Retain 的話,要記得 定時進來手動清理空間,
因為 PVC 刪除時,不會連動被刪除,但也不會掛回同一個 PVC,
重新部署時就會開一個新的空間,久而久之就變成莫名的占空間
修改完成之後,就可以將它安裝起來
安裝部署 nfs-subdir-external-provisioner
helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
-n nfs-subdir-external-provisioner --version 4.0.18 -f nfs-values.yaml其他相關指令
更新 nfs-subdir-external-provisioner 部署
helm upgrade nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
-n nfs-subdir-external-provisioner --version 4.0.18 -f nfs-values.yaml如果有參數有弄錯,可以用指令刪除部署,然後再重新部署
helm uninstall nfs-subdir-external-provisioner -n nfs-subdir-external-provisioner如果不知道 nfs-values.yaml 合併回 yaml 會長什麼樣子,
我會用 helm template 將 nfs-values.yaml 合併回 template 輸出原始 yaml,
來做比對與比較。
產生 nfs-subdir-external-provisioner templeate
helm template nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
-n nfs-subdir-external-provisioner --version 4.0.18 -f nfs-values.yaml --output-dir ./nfs-yamls正常情況會有一個 Pod 在 K8s 叢集中常駐執行
安裝 metrics-server
在自行安裝的 Vanilla Kubernetes 預設是不會安裝 metrics-server 的,
換言之,你無法使用 kubectl top node 或 kubectl top pod 等指令,
部署 Horizontal Pod Autoscaling (HPA) 也會失效,
因為他抓不到叢集 CPU、記憶體…等資訊。
所以我們讓補上 metrics-server 讓功能完整。
安裝指令也蠻簡單的,不需什麼額外設定
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml測試 metrics-server
測試 metrics-server 的方式很簡單
打上常用的這個指令可以測試
顯示每個 node 的資源使用狀況
kubectl top node顯示每個 Pod 的資源使用狀況
kubectl top pod -A就先分享到這,希望有幫助到你。
祝架設愉快!