

在當今的雲端時代,Kubernetes(簡稱 K8s)作為 Open source 的 container (容器) 編排平台,已經成為許多企業和開發者的首選。它為應用程式的部署、擴展和管理提供了一個強大且靈活的解決方案。
本篇文章將詳細介紹如何在地端 (On-premise, self-host) 伺服器上搭建 Kubernetes 環境,我們將介紹所有必要的步驟,包括環境設置、安裝必要的套件、建立節點與部署應用程式。這將是一個完整的實錄,讓讀者能夠透過這篇文章深入瞭解 K8s 的建置與運作。
若是測試環境,請使用 虛擬機 (Virtual machine, VM) 來建置,
你可以用你喜歡的虛擬機程式來架設,例如 VMWare Workstation, VirtualBox 都可以,我是使用 Promox VE 裡面的 VM 功能來完成。
測試穩定再架設實體機也不遲。
順帶一提,以下這個方式安裝方式為 Bare-metal (裸金屬、裸機)的安裝方式,
這個也叫做 Vanilla Kubernetes (翻譯:單純的 Kubernetes 安裝),
如果在其他教學有看到這樣的詞彙的話,可以意識過來。
安裝地圖
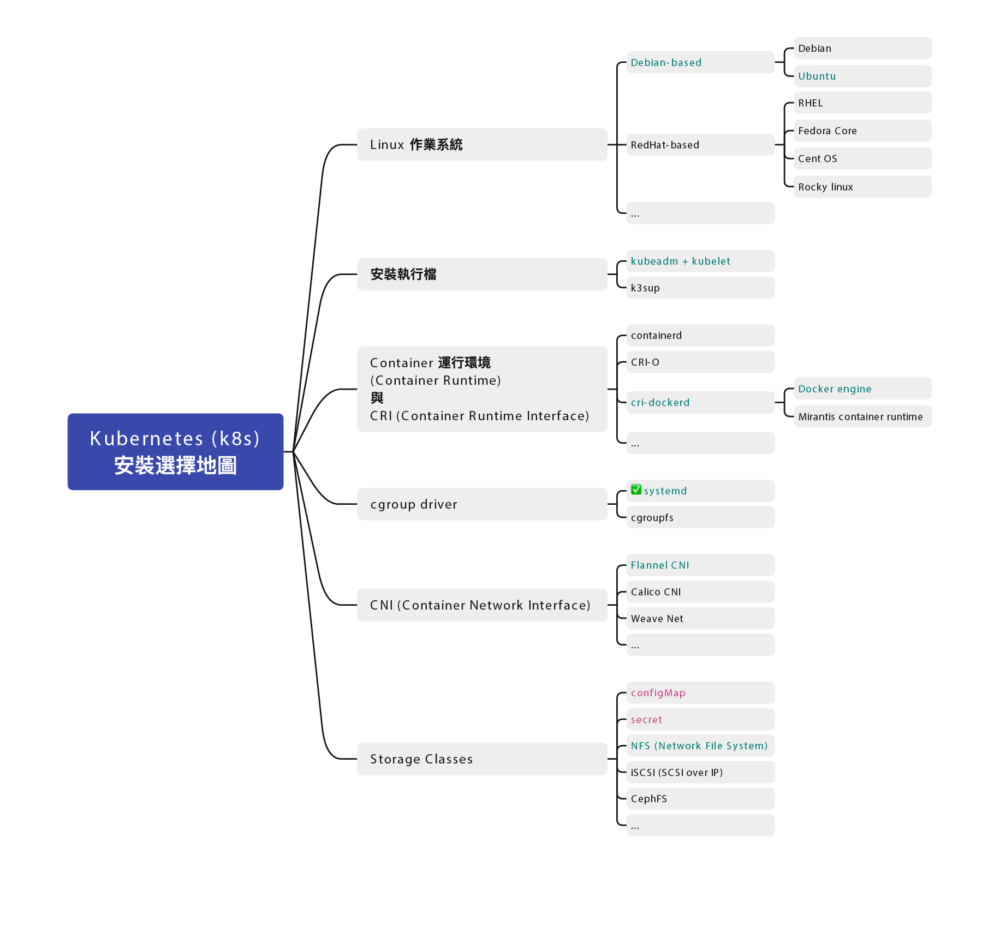
Docker 跟 Kubernetes (K8s) 發展至今,百家爭鳴,門派也很多,
安裝部署方式也不盡相同,為了避免初學者混肴,
先幫你預先選好各種所需要的元件:
作業系統
- Ubuntu Linux 22.04.2 LTS (Jammy Jellyfish)
服務們
- kubelet
- Container 運行環境 (Container Runtime):docker
- cgroup drivers: 確認為
systemd(cgroup drivers v2) - CRI (Container Runtime Interface):使用
cri-dockerd - CNI (Container Network Interface):使用
Flannel
指令們
- kubectl
- kubeadm
這篇主要關注在如何架設 Kubernetes 叢集,
除此之外,你還需要一個配合的共用儲存空間,叢集都可以存取到的儲存空間(檔案伺服器)
可以用 TrueNAS 架設一個。
虛擬機硬體建置
這邊是我 虛擬機 (VM) 的硬體部分建置設定
- 2 CPU
- 4GB Ram
- 8GB Disk 以上,建議 10GB 較穩定
註:經過測試,不要用 Promox VE 裡的 LXC Container 功能架設,
會有非常多的問題,包含權限切不乾淨等。
到時候要建立三台 VM,一台 Control Node 跟二台 Worker Node ,這是最小叢集的配置。
可以先安裝一個母版,到時候用複製 VM 的方式來達成。
虛擬機作業系統 – Ubuntu
作業系統可以是不同的發行版,我這邊用 Ubuntu 來做三台虛擬機的作業系統。
Ubuntu 可從官網下載
https://releases.ubuntu.com/
截稿時的最新 LTS 版本為 Ubuntu 22.04.2 LTS (Jammy Jellyfish)
使用 Server install image (檔名:ubuntu-22.04.2-live-server-amd64.iso) 來安裝
只安裝 SSH Server 就好,其他都先不要。
然後選項裡面有個 docker 實測發現在後續的步驟會有一些問題,請不要偷懶勾上。
<每台都做> 關掉 swap
這步驟不分角色,三台都要做
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
根據 kubeadm 的安裝文件,他有特別指示
MUST disable swap in order for the kubelet to work properly.
必須要關掉 swap 才能正確運作。
我們用以下步驟永久關閉 Swap
- 用
sed指令找尋 swap 片段,並加上註解
sudo sed -i '/ swap /s/^/#/g' /etc/fstab- 然後重新載入磁區
sudo mount -a暫時關閉 swap 可以用 swapoff 指令
sudo swapoff -a⭐️ 後記:調整 vm.swappiness 的值為零只能降低 swap 使用優先權,並不能完全關閉 swap 故移除該指令
sudo sysctl -w vm.swappiness=0確認 swap
用 sysctl 的方式來列出目前 swppiness 設定值
sysctl vm.swappiness或者用列檔案方式列出
cat /proc/sys/vm/swappiness<每台都做> 安裝 Docker
Docker 不分角色,三台都要裝
安裝文件:
https://docs.docker.com/engine/install/ubuntu/
小弟整理的一鍵安裝指令
(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
sudo apt update -y && \
sudo apt install -y ca-certificates curl gnupg && \
sudo install -m 0755 -d /etc/apt/keyrings && \
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg && \
sudo chmod a+r /etc/apt/keyrings/docker.gpg && \
echo "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null && \
sudo apt update -y && \
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin 修改 daemon.json 讓跳開預設網段
(如果沒有該檔案請自行新增之)
sudo vi /etc/docker/daemon.json內容為
{
"log-driver": "json-file",
"log-opts": {
"tag": "{{.Name}}",
"max-size": "2m",
"max-file": "2"
},
"default-address-pools": [
{
"base": "172.31.0.0/16",
"size": 24
}
],
"bip": "172.7.0.1/16"
}預設開機啟動
sudo systemctl enable --now docker驗證 Docker
可用 systemctl 指令查看是否有正常執行
sudo systemctl status docker看看是否有 Running
可以用 docker ps 查看目前所有運行中的 container
docker ps是否能夠正常顯示列表,若是初次安裝,列表是空的很正常。
Docker 版本
留下當時截稿的 Docker 版本給大家參考
# docker version
Client: Docker Engine - Community
Version: 23.0.5
API version: 1.42
Go version: go1.19.8
Git commit: bc4487a
Built: Wed Apr 26 16:21:07 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 23.0.5
API version: 1.42 (minimum version 1.12)
Go version: go1.19.8
Git commit: 94d3ad6
Built: Wed Apr 26 16:21:07 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.20
GitCommit: 2806fc1057397dbaeefbea0e4e17bddfbd388f38
runc:
Version: 1.1.5
GitCommit: v1.1.5-0-gf19387a
docker-init:
Version: 0.19.0
GitCommit: de40ad0<每台都做> 安裝 kubelet、kubeadm、kubectl 三兄弟
安裝文件:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
小弟整理的安裝指令
sudo apt update -y && \
sudo apt-get install -y apt-transport-https ca-certificates curl && \
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg && \
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list && \
sudo apt-get update -y && \
sudo apt-get install -y kubelet kubeadm kubectl && \
sudo apt-mark hold kubelet kubeadm kubectl(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
目前安裝的版本是 kubelet 1.28.2
<每台都做> 安裝 Container Runtime Interface (CRI) – cri-dockerd
這步驟不分角色,三台都要裝
https://kubernetes.io/docs/setup/production-environment/container-runtimes/
我們用 Docker Engine 推薦的 cri-dockerd
在 release 頁面找到最新版,並符合您的版本的執行檔,下載並安裝
用 deb 檔案安裝
以筆者為例,筆者用的是 Ubuntu 22.04.1 LTS (Jammy Jellyfish)
代號為 Jammy 當時最新版為 v0.3.0
所以找到了 cri-dockerd_0.3.0.3-0.ubuntu-jammy_amd64.deb
這個檔案
下載安裝檔並解開安裝
(抱歉,這套件目前沒收錄在 apt-get 套件管理程式裡,沒辦法直接 apt install)
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.4/cri-dockerd_0.3.4.3-0.ubuntu-jammy_amd64.deb && \
sudo dpkg -i cri-dockerd_0.3.4.3-0.ubuntu-jammy_amd64.deb然後請 systemctl 重新載入 daemon
最後啟動服務
systemctl daemon-reload && \
systemctl enable --now cri-docker.service從官網手動安裝 Golang
如果你的 apt-get 套件庫的 Golang 不夠新的話
我在 Redhat 那邊有遇到這情況,我把說明文件先放在這裡
到 Golang 的官網下載最新版本的 Golang 例如 1.23.2
wget https://go.dev/dl/go1.23.2.linux-amd64.tar.gz解壓縮 go1.23.2.linux-amd64.tar.gz 檔案,會得到 go 資料夾,把他搬到對應位置
tar zxvf go1.23.2.linux-amd64.tar.gz
sudo mv go /usr/lib/golang然後建立捷徑
sudo ln -s /usr/lib/golang/bin/go /usr/bin/go使用 go version 來確認版本
go version內容如下
$ go version
go version go1.23.2 linux/amd64手動編譯安裝 cri-dockerd
如果是 Ubuntu 24.04.1 LTS (Noble Numbat)
如果找不到你的版本,可能要手動編譯並安裝
以下是官方文件提供的步驟
https://github.com/mirantis/cri-dockerd#build-and-install
https://mirantis.github.io/cri-dockerd/usage/install-manually/
安裝 make 與 golang 套件
sudo apt install -y make golang用 git clone 最新的版本
git clone https://github.com/Mirantis/cri-dockerd.git編譯它 (compile)
cd cri-dockerd && \
make cri-dockerd安裝
cd cri-dockerd && \
mkdir -p /usr/local/bin && \
install -o root -g root -m 0755 cri-dockerd /usr/local/bin/cri-dockerd && \
install packaging/systemd/* /etc/systemd/system && \
sed -i -e 's,/usr/bin/cri-dockerd,/usr/local/bin/cri-dockerd,' /etc/systemd/system/cri-docker.service然後請 systemctl 重新載入 daemon
最後啟動服務
sudo systemctl daemon-reload && \
sudo systemctl enable --now cri-docker如果是服務更新版本,需要重啟服務
sudo systemctl restart cri-docker驗證 cri-docker
可用 systemctl 指令確認是否有正常運行
sudo systemctl status cri-docker確認有 Running
確認版本號
cri-dockerd --version執行紀錄
$ cri-dockerd --version
cri-dockerd 0.3.12-16-gebd9de06 (ebd9de06)裝完就會有 unix:///var/run/cri-dockerd.sock
這邊補充,其實有網友發了 Pull request,但一直沒過
https://github.com/Mirantis/cri-dockerd/pull/394
也有網友詢問 RHEL 9.4 與 Ubuntu 24.04 的做法
RHEL 9.4
https://github.com/Mirantis/cri-dockerd/issues/368
Ubuntu 24.04
https://github.com/Mirantis/cri-dockerd/issues/361
複製虛擬機 (VM)
這邊步驟就是將單純的將 虛擬機 (VM) 複製二份成三台,並全部啟動。
以下分別闡述複製完要做的事情
重新產生 Machine-id
用以下指令重新產生 Machine-id
sudo rm /etc/machine-id && \
sudo systemd-machine-id-setup修改 Hostname (主機名稱)
sudo hostnamectl set-hostname k8s-node1分別改成對應的主機名稱
重新設定 ssh,產生全新的 known-host
sudo ssh-keygen -A && \
sudo dpkg-reconfigure openssh-server確認 Machine-id
sudo cat /sys/class/dmi/id/product_uuid確認 Hostname
hostname確認網卡 Mac address 位址
ip link或者
ifconfig都可以,如果沒有 ifconfig 指令要安裝 net-tools
sudo apt install -y net-toolshttps://superuser.com/questions/636924/regenerate-linux-host-fingerprint
如果有需要的話,可以用 dhclient 指令重新取 DHCP 的 IP
(基本上你重新產生 Machine-id 的話,就會視為別台電腦了)
sudo dhclient -r<每台都做> 設定主機對應
叢集的三台機器做出來,還不知道彼此,
這邊用 /etc/hosts 檔案來讓主機們各自找到彼此
sudo vi /etc/hosts根據每台主機的 IP 位址與主機名稱
192.168.1.100 k8s-ctrl
192.168.1.101 k8s-node1
192.168.1.102 k8s-node2IP 位址在前,主機名稱在後,用 tab 分隔。
先整理好內容,再各自寫在每一台上面,每一台主機都會看到同一份資料。
確認 cgroup drivers 為 systemd
直接講結論,目前最新使用的是 systemd (cgroup Version: 2)
查看 docker 的 cgroup
docker info | grep -i cgroup執行結果
# docker info | grep -i cgroup
Cgroup Driver: systemd
Cgroup Version: 2
cgroupns查看 kubelet 的 cgroup
sudo cat /var/lib/kubelet/config.yaml | grep cgroup執行結果
$ sudo cat /var/lib/kubelet/config.yaml | grep cgroup
cgroupDriver: systemd可以確認是否為 systemd (cgroup Version: 2)
如果 docker 不為 systemd
可以在 daemon.json手動加上
sudo vi /etc/docker/daemon.json這個段落
"exec-opts": [
"native.cgroupdriver=systemd"
],重啟 docker
sudo systemctl restart docker如果 kubelet 不為 systemd 就手動修改之
sudo vi /var/lib/kubelet/config.yaml重啟 kubelet
sudo systemctl restart kubelet<每台都做> 設定網路雜項值
這邊設定網路連線轉發 IPv4 位址並讓 iptables 查看橋接器的流量
用文件提供的指令操作,等等一句一句解釋:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF請 Kubernetes (K8s) 引用載入 br_netfilter, overlay 二個核心模組
sudo modprobe overlay && \
sudo modprobe br_netfilter啟用 br_netfilter, overlay 二個核心模組
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF設定轉發 IPv4 位址,讓 iptables 查看橋接器的流量
sudo sysctl --system再不起重新啟動電腦情況下,套用設定值
檢查驗證
檢查 br_netfilter, overlay 二個核心模組有沒有被正確載入可以用以下二個指令
lsmod | grep br_netfilter
lsmod | grep overlay檢查
net.bridge.bridge-nf-call-iptablesnet.bridge.bridge-nf-call-ip6tablesnet.ipv4.ip_forward
這幾個系統變數是否有設定為 1,可以用 sysctl 指令來檢查:
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward設定 Control plane node(控制平台) (舊名 Master node)
終於要來設定 Control plane (控制平台) 了,如果有其他教學看到 Master node 的話,
別擔心,指的是同一件事情。
利用 kubeadm init 指令來初始化,並代入這些參數:
sudo kubeadm init \
--kubernetes-version 1.28.2 \
--control-plane-endpoint=192.168.1.100 \
--apiserver-advertise-address=192.168.1.100 \
--node-name k8s-ctrl \
--pod-network-cidr=10.244.0.0/16 \
--cri-socket unix:///var/run/cri-dockerd.sock參數說明
control-plane-endpoint
指明 Control plane (控制平台) 是哪個網址,這邊設定好目前這台 IP 位址即可,假設為 192.168.1.100
(這設定值可省略)apiserver-advertise-address
指明 API server 的廣播地址,預設就是 Control plane (控制平台) IP 位址,假設為 192.168.1.100
(這設定值可省略)node-name
指明 Control plane (控制平台) 的名字,這裡跟主機名稱一致即可。pod-network-cidr
指明 pod 內部網路使用的網段,這邊因為配合 Flannel CNI,請保留10.244.0.0/16請不要修改。cri-socket
指明使用的 CRI 使用unix:///var/run/cri-dockerd.sock這設定值 請不要修改。
記錄一下運作的樣子
# kubeadm init --pod-network-cidr=10.244.0.0/16 --cri-socket unix:///var/run/cri-dockerd.sock
[init] Using Kubernetes version: v1.28.2
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
W0503 18:35:29.693213 1321 images.go:80] could not find officially supported version of etcd for Kubernetes v1.28.2, falling back to the nearest etcd version (3.5.7-0)
W0503 18:35:46.627127 1321 checks.go:835] detected that the sandbox image "registry.k8s.io/pause:3.6" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "registry.k8s.io/pause:3.9" as the CRI sandbox image.
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-ctrl kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.1.100]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-ctrl localhost] and IPs [192.168.1.100 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-ctrl localhost] and IPs [192.168.1.100 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
W0503 18:36:08.496065 1321 images.go:80] could not find officially supported version of etcd for Kubernetes v1.28.2, falling back to the nearest etcd version (3.5.7-0)
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 8.502958 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-ctrl as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node k8s-ctrl as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: c1hnqs.c4imcnzqxqry62d0
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.100:6443 --token cxxxxs.c4xxxxxxxxxxxxd0 \
--discovery-token-ca-cert-hash sha256:103d7xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx5b1b6如果沒意外的話,完成之後會看到
Your Kubernetes control-plane has initialized successfully!別太高興,設定還沒完,先把 kubeadm join 語句先存起來備用
然後依照步驟,
若是 root 使用者,
在 .bash_profile 或者 .zsh_profile 設定環境變數
export KUBECONFIG=/etc/kubernetes/admin.conf若是一般使用者,請依照指令依序設定
mkdir -p $HOME/.kube && \
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config && \
sudo chown $(id -u):$(id -g) $HOME/.kube/config註:加入 token 是有期限的,如果隔太久沒有整個步驟做完,
或者忘記了、被洗掉了,可以用指令重新生成加入指令
kubeadm token create --print-join-command\<Control plane 做> 安裝 Helm 套件管理程式
Helm 是 Kubernetes (K8s) 所使用的套件管理程式,
類似 apt-get 可以方便我們安裝元件,免去一點設定的雷
Helm 只要裝在 Control plane (舊名 Master node) 就可以了
安裝文件
https://helm.sh/docs/intro/install/
從 APT 安裝(推薦),可用小弟整理之一鍵安裝指令
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null && \
sudo apt install apt-transport-https --yes && \
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list && \
sudo apt update -y && \
sudo apt install -y helm(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
也可從 Script 安裝
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 && \
chmod 700 get_helm.sh && \
./get_helm.sh二者效果相同,擇一安裝即可。
\<Control plane 做> 安裝 Flannel CNI
https://github.com/flannel-io/flannel
使用 Helm 安裝 Flannel,將之安裝在 kube-flannel 的 namespace,可用小弟整理之一鍵安裝指令
Flannel 只要在 Control plane (舊名 Master node) 上面下指令,就會部署到整個叢集。
可以使用以下整理之指令一鍵安裝
kubectl create ns kube-flannel && \
kubectl label --overwrite ns kube-flannel pod-security.kubernetes.io/enforce=privileged && \
helm repo add flannel https://flannel-io.github.io/flannel/ && \
helm install flannel --set podCidr="10.244.0.0/16" --namespace kube-flannel flannel/flannel(科技發展迅速,整理的安裝文件有可能會過時,如果有更新版,請參考官方文件)
指令意思大致為:
- 建立一個 namespace (命名空間)名叫
kube-flannel - 給定
kube-flannel特權的權限 - 加入 repo 網址
- 用 helm 安裝 Flannel
設定 Worker node
這下終於可以設定 Worker node 了
還記得剛剛留下來的指令
kubeadm join 192.168.1.100:6443 --token cxxxxs.c4xxxxxxxxxxxxd0 \
--discovery-token-ca-cert-hash sha256:103d7xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx5b1b6什麼?忘記了?
可以用指令重新生成加入指令
kubeadm token create --print-join-command出現 kubeadm join 指令之後,加上指明 cri-socket 就可以執行了
變成這樣
sudo kubeadm join 192.168.1.100:6443
--token cxxxxs.c4xxxxxxxxxxxxd0 \
--discovery-token-ca-cert-hash sha256:103d7xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx5b1b6 \
--cri-socket unix:///var/run/cri-dockerd.sock記錄一下運作情形
$ kubeadm join 192.168.1.100:6443
--token cxxxxs.c4xxxxxxxxxxxxd0 \
--discovery-token-ca-cert-hash sha256:103d7xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx5b1b6 \
--cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.這樣就加入叢集了
查看 kubelet Log
另外這二個指令,對於 kubelet 的啟動不了的問題,也會有一些方向
查看 kubelet 狀態
systemctl status kubelet查看 kubelet 的 Log
journalctl -xeu kubelet最後,一個小小經驗談,
--control-plane-endpoint 和 --apiserver-advertise-address 的 IP 可以再次確認是否有打錯字,這也會造成錯誤
重設整個叢集
如果整個叢集有其他問題,做爛了,可以用以下方法重新設定
進到每一台 node 裡面,利用 kubeadm reset 重置,記得代入 cri-socket
如下:
kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock記錄一下運作情形
$ kubeadm reset -f --cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks
W0507 02:43:32.160215 1264 removeetcdmember.go:106] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] Deleted contents of the etcd data directory: /var/lib/etcd
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
W0507 02:43:32.169757 1264 cleanupnode.go:134] [reset] Failed to evaluate the "/var/lib/kubelet" directory. Skipping its unmount and cleanup: lstat /var/lib/kubelet: no such file or directory
[reset] Deleting contents of directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.它會提示你,有些防火牆規則並不會完全刪掉
可以刪掉 cni 資料夾來重置
rm -rf /etc/cni/net.d對應文件:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-reset/
\<Control plane 做> 測試檢查叢集
測試 Kubernetes 是否正常運作,
在 Control plane (控制平台) 裡可以用二個指令觀察一下:
取得所有的 Pods
用 kubectl get pods 指令取得 Pod,加上 -A 代表包含所有 namespace (命名空間)
以下指令就是取得所有的 Pods
kubectl get pods -A取得所有的 pods
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-8rtvc 1/1 Running 0 30s
kube-flannel kube-flannel-ds-9w2vw 1/1 Running 0 30s
kube-flannel kube-flannel-ds-jdndp 1/1 Running 0 30s
kube-system coredns-5d78c9869d-df989 1/1 Running 0 4m20s
kube-system coredns-5d78c9869d-s8ftg 1/1 Running 0 4m19s
kube-system etcd-k8s-ctrl 1/1 Running 0 4m35s
kube-system kube-apiserver-k8s-ctrl 1/1 Running 0 4m33s
kube-system kube-controller-manager-k8s-ctrl 1/1 Running 0 4m35s
kube-system kube-proxy-2qrjj 1/1 Running 0 4m19s
kube-system kube-proxy-bpk94 1/1 Running 0 3m51s
kube-system kube-proxy-mgrjn 1/1 Running 0 3m57s
kube-system kube-scheduler-k8s-ctrl 1/1 Running 0 4m36s你應該要看到:
kube-flannel的若干個 Pod 為Running
(若是 Pending 或者 CrashLoopBackOff 可能要除錯)kube-system(K8s 核心元件) 的二個coredns的 Pod 為Running
(若是 Pending 或者 CrashLoopBackOff 可能要除錯)kube-system(K8s 核心元件) 的etcd為Runningkube-system(K8s 核心元件) 的kube-controller-manager的 Pod 為Runningkube-system(K8s 核心元件) 的kube-apiserver的 Pod 為Runningkube-system(K8s 核心元件) 的kube-scheduler的 Pod 為Runningkube-system(K8s 核心元件) 的若干個kube-proxy的 Pod 為Running
當然,放在 kube-system 裡面的 Pod 屬於系統保留的,請勿更動修改。
取得所有 nodes (主機節點)
你可以用 kubectl get nodes -A 指令來取得所有運作的 nodes
kubectl get nodes -A
NAME STATUS ROLES AGE VERSION
k8s-ctrl Ready control-plane 4m40s v1.28.2
k8s-node1 Ready <none> 3m59s v1.28.2
k8s-node2 Ready <none> 3m53s v1.28.2你應該要看到你的叢集,三台都是 Ready 的